
RAG is often the fastest way to make an LLM useful with your company knowledge, without retraining a model every time a policy, product spec, or ticket history changes.
The catch is that “just add a vector database” rarely works for long. Teams usually get stuck on the same issues: answers that sound confident but cite the wrong doc, latency that surprises you in production, and a pipeline that nobody can reliably evaluate.
This guide focuses on practical use cases, what a retrieval augmented generation architecture typically looks like, and the design choices that actually move quality: chunking, embeddings, hybrid search, reranking, prompt structure, and evaluation.
Where RAG delivers real value (and where it doesn’t)
RAG shines when your “source of truth” changes more often than you can justify training cycles, and when the answer needs grounding in specific passages, not general world knowledge.
- Customer support copilots: draft replies from KB articles, past resolutions, warranty terms, and account notes.
- Internal knowledge assistants: HR policies, IT runbooks, engineering RFCs, incident postmortems.
- Sales and solutions engineering: security questionnaires, product one-pagers, pricing rules, feature compatibility.
- Compliance-aware Q&A: point to the exact policy section and keep an audit trail of sources.
- Document-heavy workflows: contract clause lookup, RFP summarization with citations, research synthesis.
On the other hand, RAG is not a silver bullet for tasks where you need new skills (for example, a model that must write code in your internal DSL), or where the “right answer” is more about reasoning than retrieval. In those cases, you might still use retrieval, but you’ll also lean on better prompting, tool use, or model adaptation.
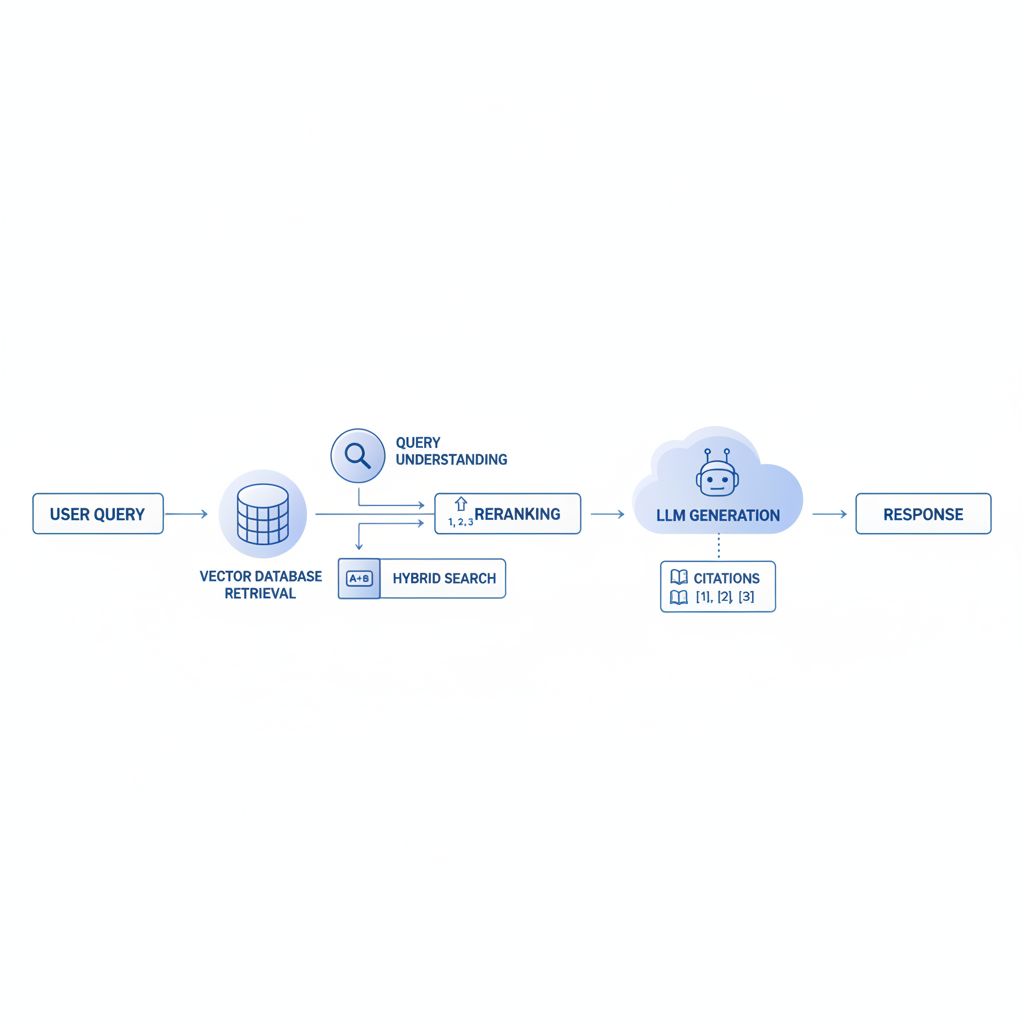
Retrieval augmented generation architecture: the moving parts that matter
A retrieval augmented generation architecture usually breaks into four layers: content (your documents), indexing (how you store/search), retrieval/reranking (how you pick evidence), and generation (how the LLM responds with guardrails).
1) Content & ingestion
- Connectors (Drive, Confluence, Zendesk, SharePoint, Git, web pages)
- Normalization (remove boilerplate, keep headings, preserve tables when possible)
- Access control mapping (don’t “retrieve what the user can’t see”)
2) Indexing & storage
- Embeddings + vector index
- Optional keyword index for hybrid search
- Metadata fields (product, region, doc type, updated_at, permission groups)
3) Retrieval and reranking
- Query rewriting (optional) to make the question searchable
- Candidate retrieval (top-k from vector and/or lexical)
- Reranking to select the most relevant evidence passages
4) Generation layer
- Prompt template that enforces “answer from sources” behavior
- Citations and refusal behavior when evidence is weak
- Post-processing (formatting, structured JSON, redaction)
According to NIST, evaluation and risk management should be part of any AI system lifecycle, and that mindset fits RAG well: you’re building a system, not a demo, so measure what matters early.
RAG pipeline design: a pragmatic sequence that holds up in production
A workable rag pipeline design usually starts simple, then earns complexity only when you can prove the delta in quality or cost.
- Step A: define “grounded” output: citations required, or a strict “I don’t know” when sources fail.
- Step B: build indexing with metadata: you’ll want filters sooner than you think (region, product line, version).
- Step C: add hybrid retrieval: especially for part numbers, error codes, names, and exact phrases.
- Step D: add reranking: helps when your top-k contains near-misses that confuse the LLM.
- Step E: evaluate continuously: regression tests for retrieval and generation, not just vibe checks.
Latency usually comes from too many retrieval calls, overly large context windows, or rerankers that run on huge candidate sets. A common compromise: retrieve 40–100 candidates cheaply, rerank down to 5–12 passages, then generate with a tighter prompt.

Key technical choices: embeddings, chunking, hybrid search, reranking
Most “RAG quality” problems trace back to retrieval, not the model. If the system fetches the wrong evidence, prompt tricks rarely save it.
Embedding model selection
Embedding model selection depends on your domain language and query patterns. General-purpose embeddings often work for broad knowledge bases, but specialized language (medical, legal, deep technical) sometimes benefits from domain-tuned embeddings or at least careful benchmarking.
- Test on your own queries, including short, messy, real user questions.
- Watch for “near-duplicate confusion” where different versions of the same doc compete.
- Keep an eye on multilingual needs, even in US-only products, because internal docs often include mixed language snippets.
Chunking strategies for RAG
Chunking strategies for rag are where many teams accidentally destroy meaning. Chunks that are too small lose context, too large waste tokens and dilute relevance.
- Start with structure-aware chunks: split by headings, sections, or Q&A pairs, not arbitrary character counts.
- Use overlap sparingly: small overlaps help continuity, big overlaps inflate the index and increase duplicates.
- Attach metadata: section title, doc title, version, product, and effective date are often as important as the text.
Hybrid search for RAG
Hybrid search for rag combines semantic retrieval with keyword or BM25-style retrieval. It’s especially helpful for identifiers, error codes, or terms where exact match matters.
- Use lexical retrieval as a “safety net” for proper nouns and SKUs.
- Blend scores or merge candidate sets, then let reranking pick winners.
Reranking in RAG systems
Reranking in rag systems is often the cleanest quality jump after you have a reasonable index. A reranker (often a cross-encoder) judges query-passage relevance more precisely than embeddings alone.
- Rerank smaller candidate pools to control cost and latency.
- Prefer reranking when you see “almost right” passages outranking the truly correct one.
Vector database for RAG: how to choose without over-optimizing
A vector database for rag is more about operational fit than hype. Most mainstream options handle similarity search well; the differences show up in ingestion speed, filtering, hybrid search support, scaling, and governance.
| Decision factor | What to look for | Why it matters in RAG |
|---|---|---|
| Metadata filtering | Fast filters, indexes on fields | Keeps retrieval scoped to the right product, region, version, or permission set |
| Hybrid retrieval | Native keyword + vector, or easy integration | Improves recall for codes, names, and exact phrases |
| Freshness | Streaming updates, reindex workflows | Old chunks cause “confident wrong” answers when policies change |
| Latency & scale | P95 latency, caching, sharding | User experience breaks when retrieval adds seconds |
| Security & compliance | Encryption, RBAC, audit logs | Critical for internal assistants and regulated data |
If you already run Elasticsearch/OpenSearch, adding vectors there can be a sensible starting point. If your stack prefers managed services, a hosted vector store can reduce ops load. Either way, plan for migrations: embedding models change, chunking evolves, and you’ll reindex.
RAG vs fine tuning: how teams usually decide
Rag vs fine tuning is less a rivalry than a sequencing question. Many production systems use both, but not always at the same time.
- Choose RAG when knowledge changes frequently, you need citations, or you want fast iteration with minimal model training.
- Consider fine tuning when you need consistent style, domain-specific behavior, tool calling patterns, or you’re encoding “how to respond,” not “what is true right now.”
- Combine them when you want a tuned model that follows strict policies, while retrieval supplies fresh facts.
One practical rule: if the problem is “the model doesn’t know our latest rules,” retrieval is usually the first fix. If the problem is “the model won’t follow our format or process,” tuning or stronger prompting may be more direct.
Evaluation, prompting, and a simple rollout checklist
Rag evaluation metrics should reflect two realities: retrieval can fail quietly, and generation can sound right while being wrong. Measure both layers.
Evaluation that’s actually actionable
- Retrieval recall@k: does the correct passage appear in the top-k candidates?
- Reranker success rate: when the right passage exists, does it rise to the final set?
- Groundedness: are claims supported by cited passages, or do you see extra unsupported statements?
- Answer usefulness: human rating for “solves the task,” not just “sounds fluent.”
- Latency and cost: track by step, retrieval vs rerank vs generation.
According to OpenAI, using evaluations and test sets is a standard practice to improve reliability in LLM applications, and RAG systems benefit even more because you can isolate whether retrieval or generation caused the miss.
Prompt engineering for RAG (what tends to work)
Prompt engineering for rag is mostly about narrowing degrees of freedom.
- Require citations and instruct the model to answer only from provided context.
- Define refusal behavior: if sources don’t cover the question, say what’s missing and ask a clarifying question.
- Keep context tidy: include titles, section headers, and short snippets, not full documents.
Rollout checklist (practical, not fancy)
- Start with one use case and a bounded document set you can keep clean.
- Create a 30–100 query test set from real tickets or internal searches, then keep adding failures.
- Add logging: query, retrieved chunk IDs, reranked list, final citations, latency.
- Set guardrails: block sensitive categories, enforce permissions, redact PII where required.
- Plan reindexing: version your embeddings and chunking so changes are reversible.

Conclusion: make RAG boring, measurable, and useful
RAG works best when you treat it like search plus controlled generation, not magic. Get retrieval right with solid chunking, sensible embeddings, and hybrid search where exact matches matter, then add reranking and strict prompts to keep answers grounded.
If you want one next step: pick a single high-value workflow, build a small evaluation set from real queries, and iterate until your retrieval consistently surfaces the right evidence before you spend time polishing model output.